Meta-analysis can be defined as a statistical tool or a formal process of combining the results from multiple studies [1]. This allows the analysis of the results from various scientific studies, which are often not performed in the same place or using the same method [2]. Notably, both randomized clinical trials and observational studies are prone to a wide range of biases, and meta-analysis may lend spurious precision to questionable results. Therefore, the focus of meta-analysis of observational studies should be an evaluation of heterogeneity [1].
What is a proportion study?
“Proportion study” is a study where the main outcome is a proportion (e.g., prevalence, incidence, percentage) of an event in a population.
For example:
25 people with epilepsy out of 100 participants
18% prevalence of a disease in a community
Why the meta-analysis of proportion is different?
Most meta-analyses aim to evaluate the effect of an intervention or exposure compared with a comparator. The result is a pooled estimate of effect size which includes risk ratio, odds ratio, incidence rate ratio, or mean difference [3]. In contrast, systematic reviews of studies estimating the proportion of a particular disease or health status typically involve a single study group, and the outcomes (e.g., prevalence, incidence, etc.) do not behave like conventional effect sizes. Some characteristics of the proportion are as follows:
Proportions are bounded between 0 and 1, and do not behave like normal continuous data
Variances are not constant
Zero-event studies can happen. In that case, variance may become zero.
Heterogeneity is usually very high
Let examine the characteristics of the proportion. Here,
We will first create a data set with variables: Study, n: Study population, and y: Event.
Then, we will calculate proportions and related variance.
Then, we will examine the characteristics of proportion data.
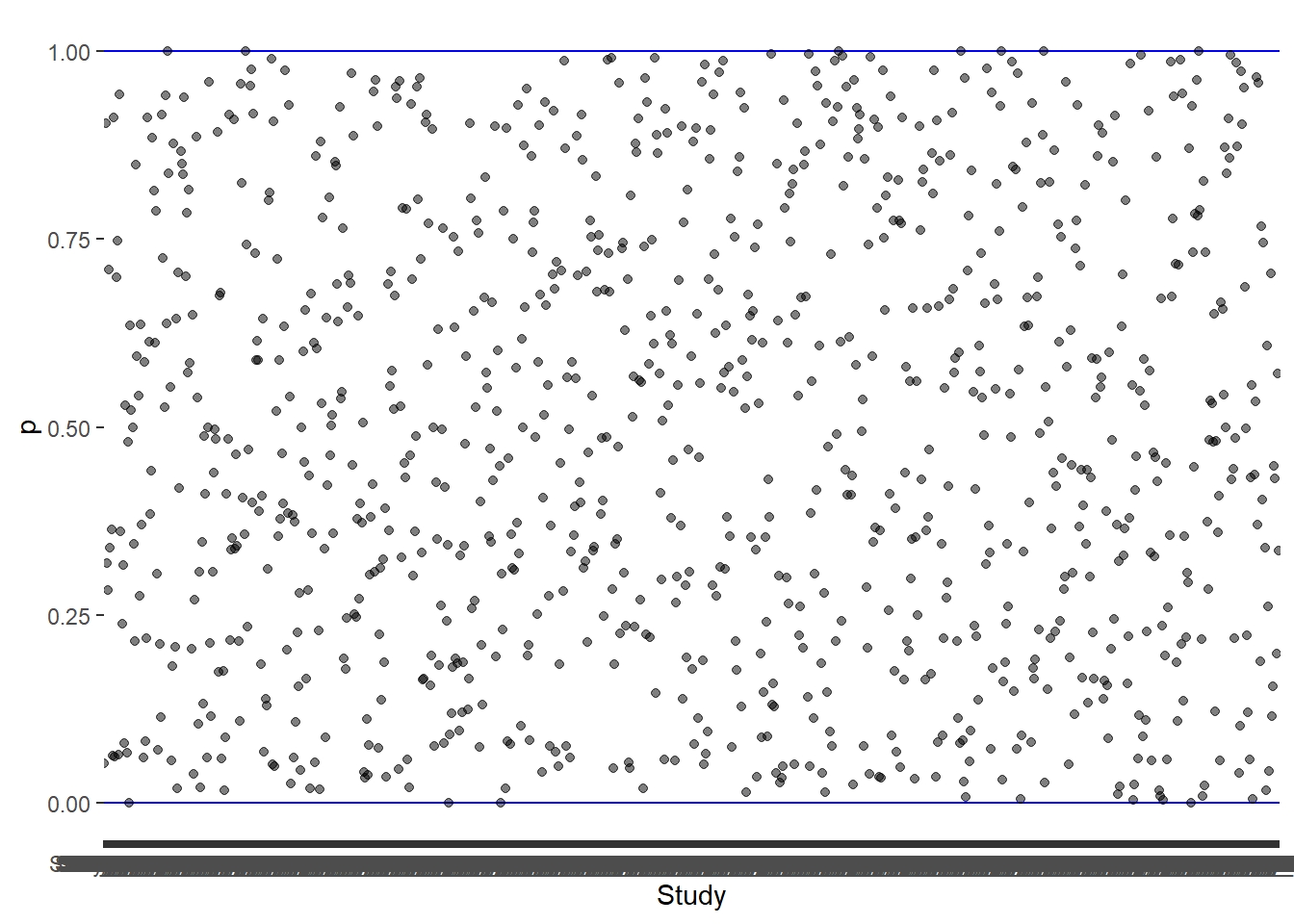
1. Proportions are bounded between 0 and 1
Code
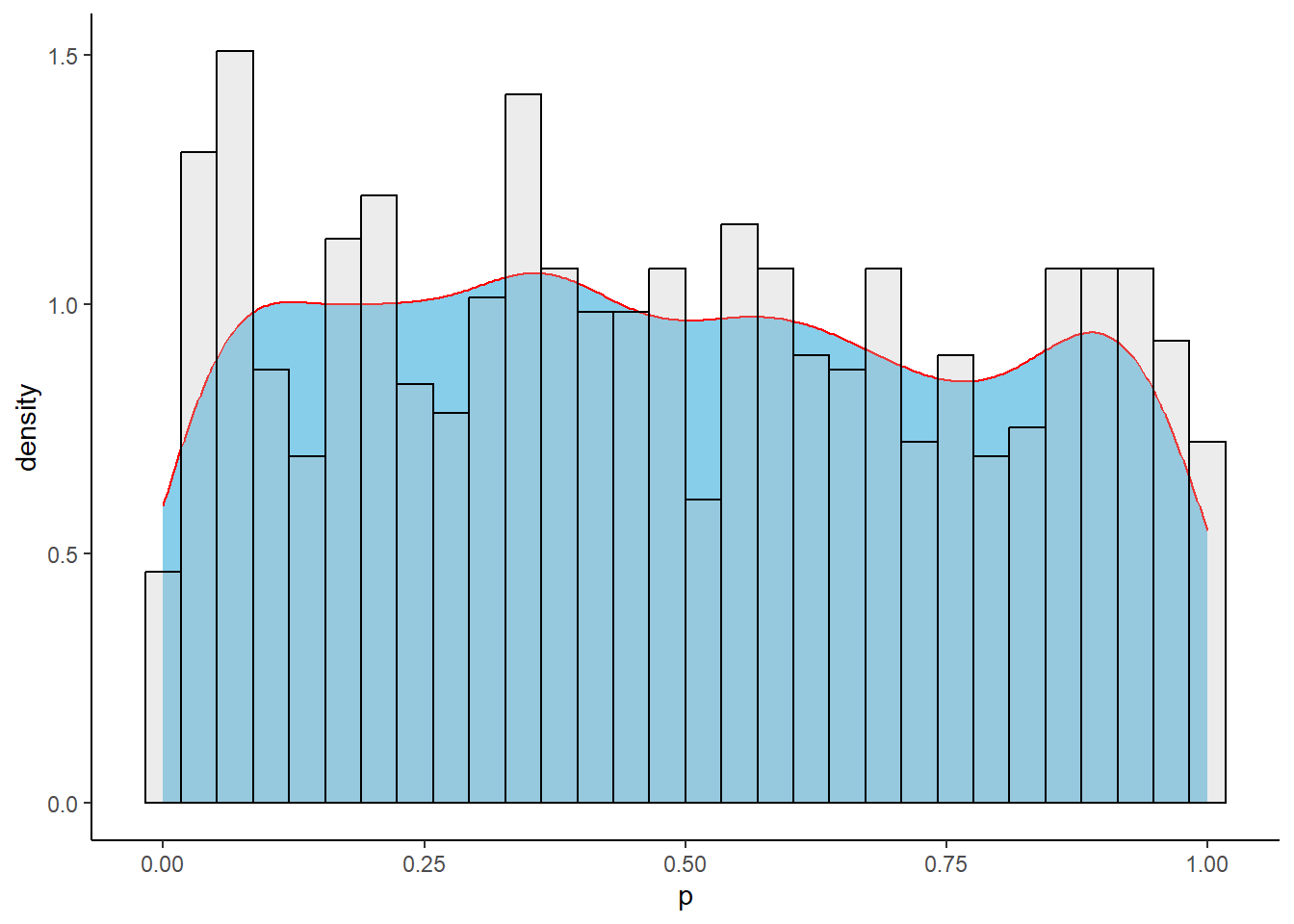
## Create data setset.seed(123)data <-data.frame(Study =paste0("Study_", 1:1000),n =sample (1:1000,1000))data$y <-mapply(function(n) sample(0:n,1), data$n)## Calculate the propotiondata$p <- data$y/data$n## Calculate variance (= p[1-p]/n)data$var_p <- (data$p*(1-data$p))/data$n## Plot the proportion (Character 1)ggplot(data,aes(Study,p))+geom_hline(yintercept =0, color ="blue", linewidth =0.5)+geom_hline(yintercept =1, color ="blue", linewidth =0.5)+geom_point(alpha =0.5)
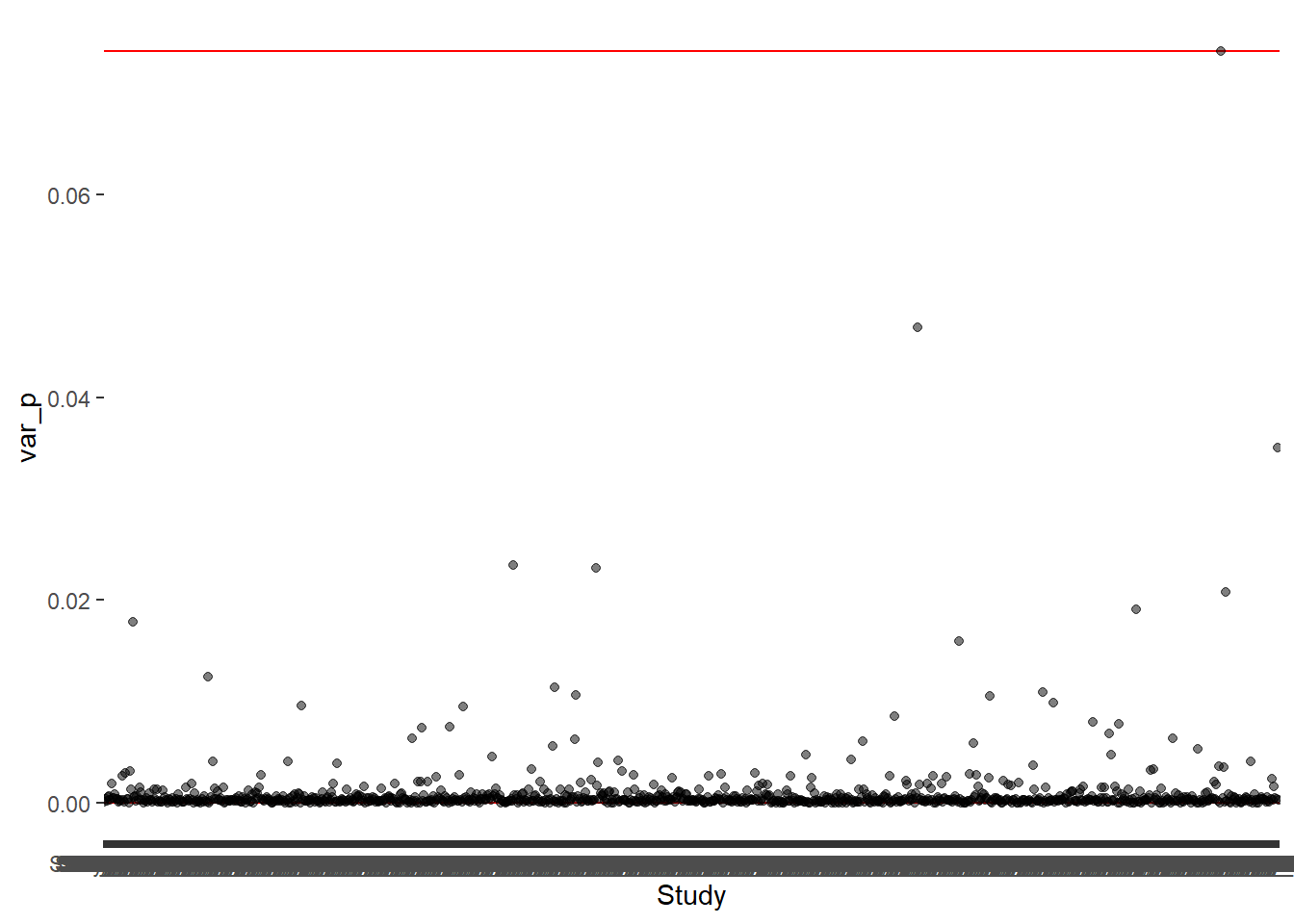
2. Variances are not constant
This can be visualize as -
Code
## Plot the varianceggplot(data,aes(Study,var_p))+geom_hline(yintercept =0, color ="red", linewidth =0.5)+geom_hline(yintercept =max(data$var_p), color ="red", linewidth =0.5)+geom_point(alpha =0.5)
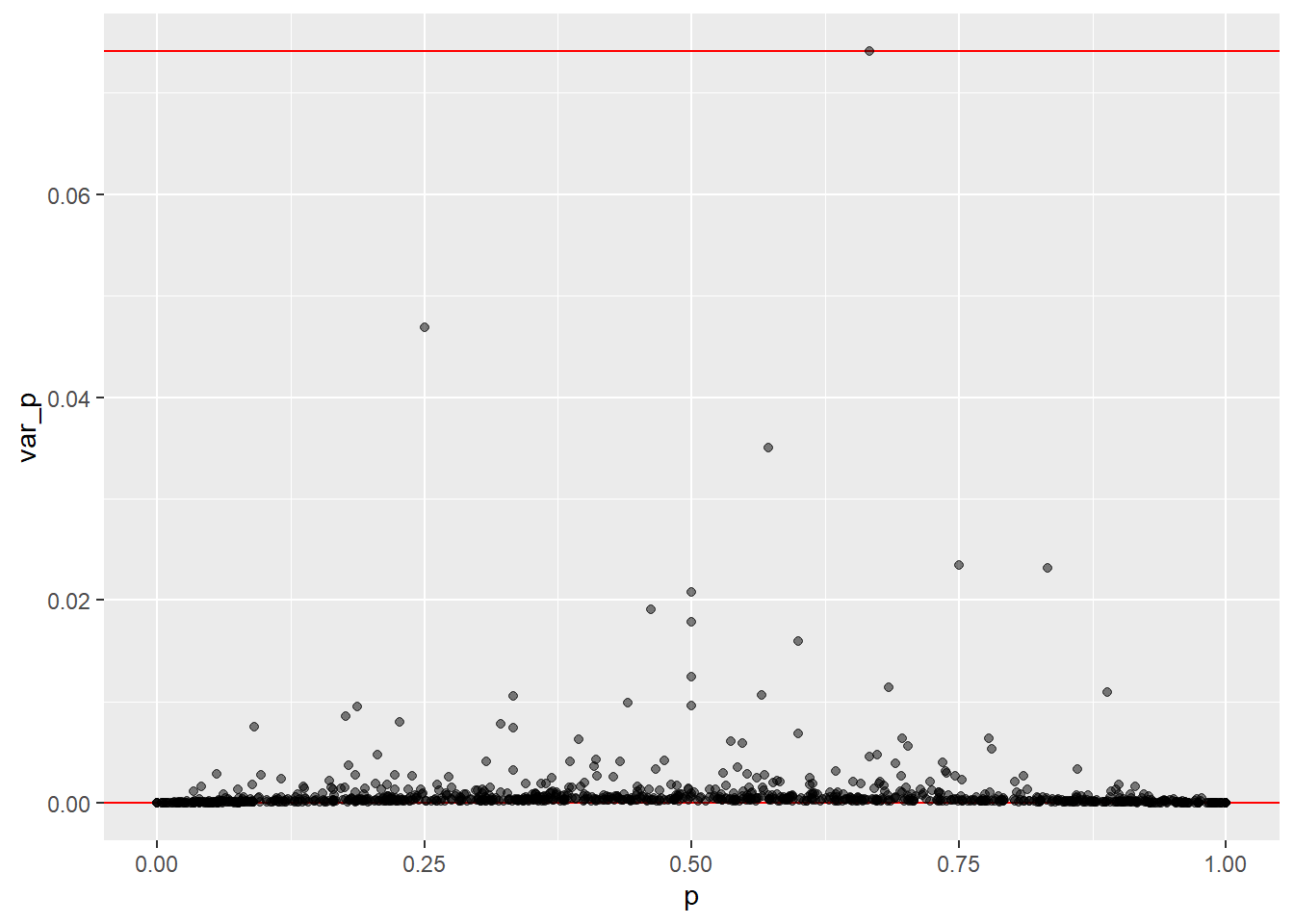
Or as Raw proportions vs variance
Code
## Plot the varianceggplot(data,aes(p,var_p))+geom_hline(yintercept =0, color ="red", linewidth =0.5)+geom_hline(yintercept =max(data$var_p), color ="red", linewidth =0.5)+geom_point(alpha =0.5)
3. Zero-event studies can happen
Code
data_0 <- data %>%filter(p ==0)data_0
Study n y p var_p
1 Study_117 51 0 0 0
2 Study_362 106 0 0 0
3 Study_401 10 0 0 0
4 Study_930 1 0 0 0
Look at the column of variance (var_p). They are zeros.
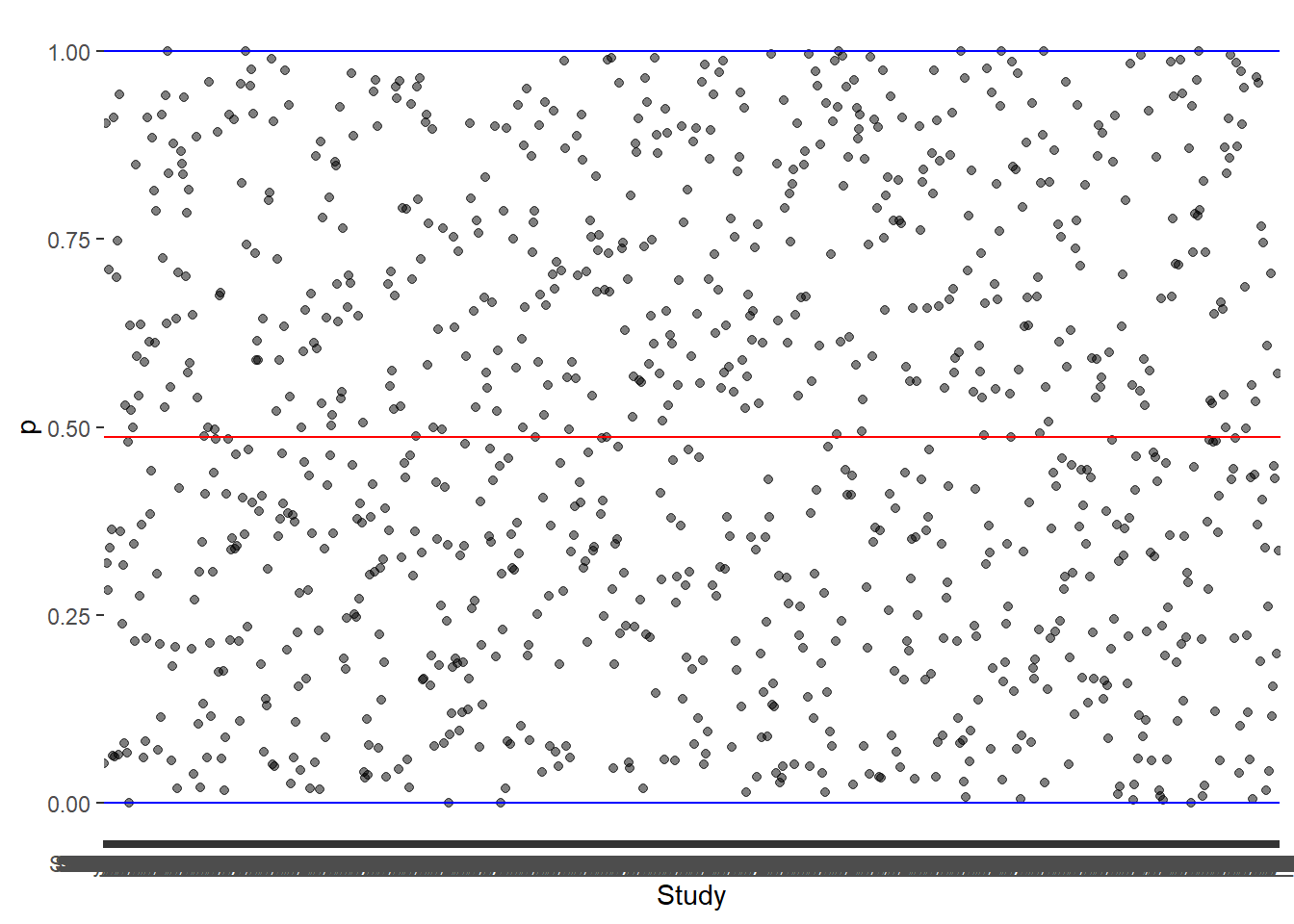
4. Heterogeneity is usually very high
Code
mean_p <-mean(data$p, na.rm =TRUE)## Plot the proportion (Character 1)ggplot(data,aes(Study,p))+geom_point(alpha =0.5) +geom_hline(yintercept =0, color ="blue", linewidth =0.5)+geom_hline(yintercept =1, color ="blue", linewidth =0.5)+geom_abline(intercept = mean_p, slope =0, color ="red")
But, when conducting a meta-analysis of proportions (pooling a single proportion across multiple studies), several foundational assumptions must be met to ensure the statistical validity and clinical relevance of your pooled estimate. Among several assumptions one most important assumption is the normality of the effect sizes (i.e., proportions).
How can we normalize the data?
To stabilize variance and improve normality, proportions can be transformed to another scale. Some such transformations are -
Logit transformation
Log transformation
Arcsine transformation
Freeman–Tukey double arcsine transformation
1. Logit transformation
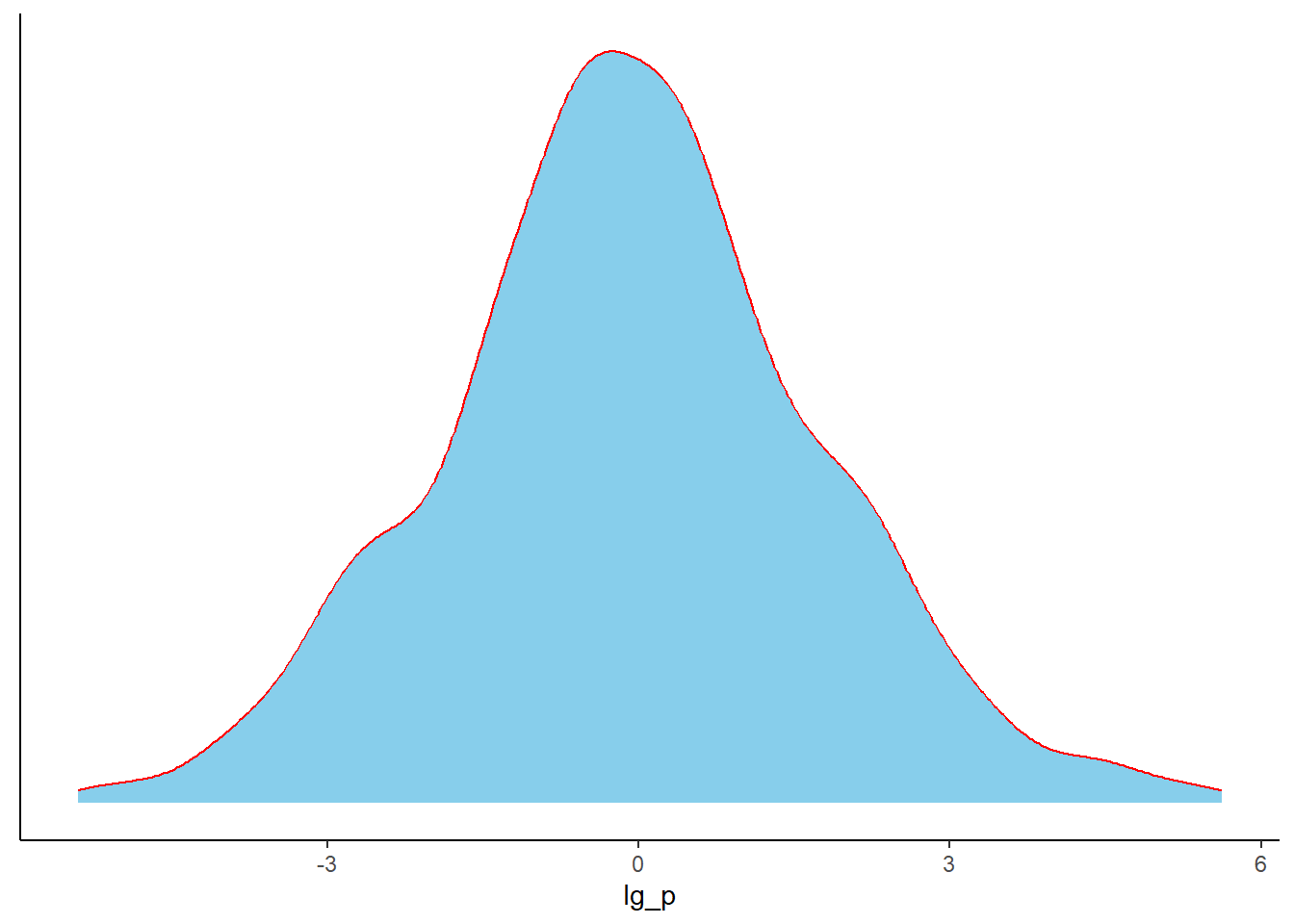
Let see what happen to our example proportions if we apply logit transformation to them.
\[
Logit (p) = log (\frac{p}{1-p})
\]
Code
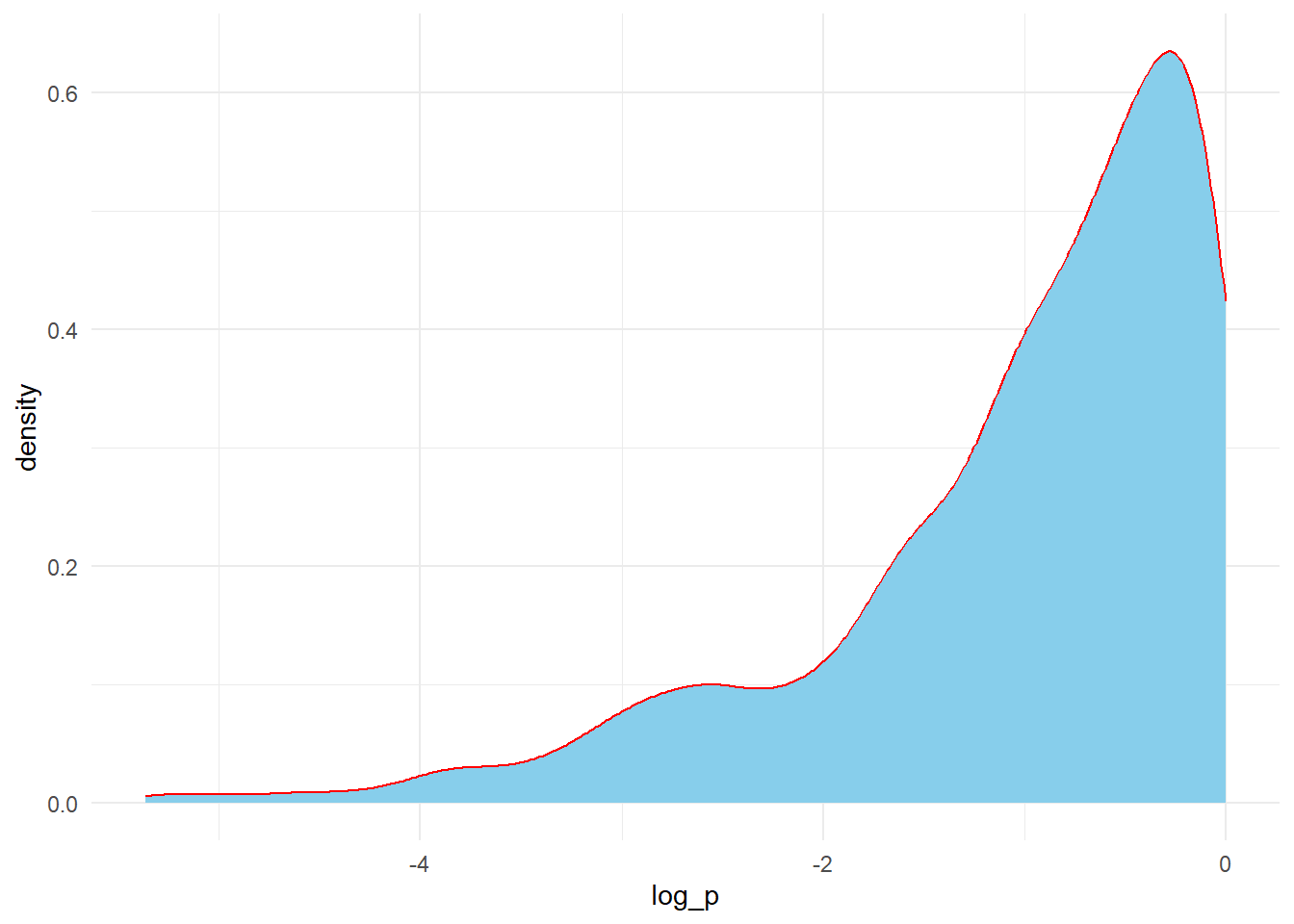
## Perform logit transformation of the proportions and plot themdata %>%filter(p>0,p<1) %>%# Here, we are losing some data where data has 0% or 100% proportionmutate(lg_p =log(p/(1-p))) %>%ggplot(.,aes(x = lg_p))+geom_density(color ="red",fill ="skyblue")+theme_classic()+theme(axis.title.y =element_blank(),axis.text.y =element_blank(),axis.ticks.y =element_blank())
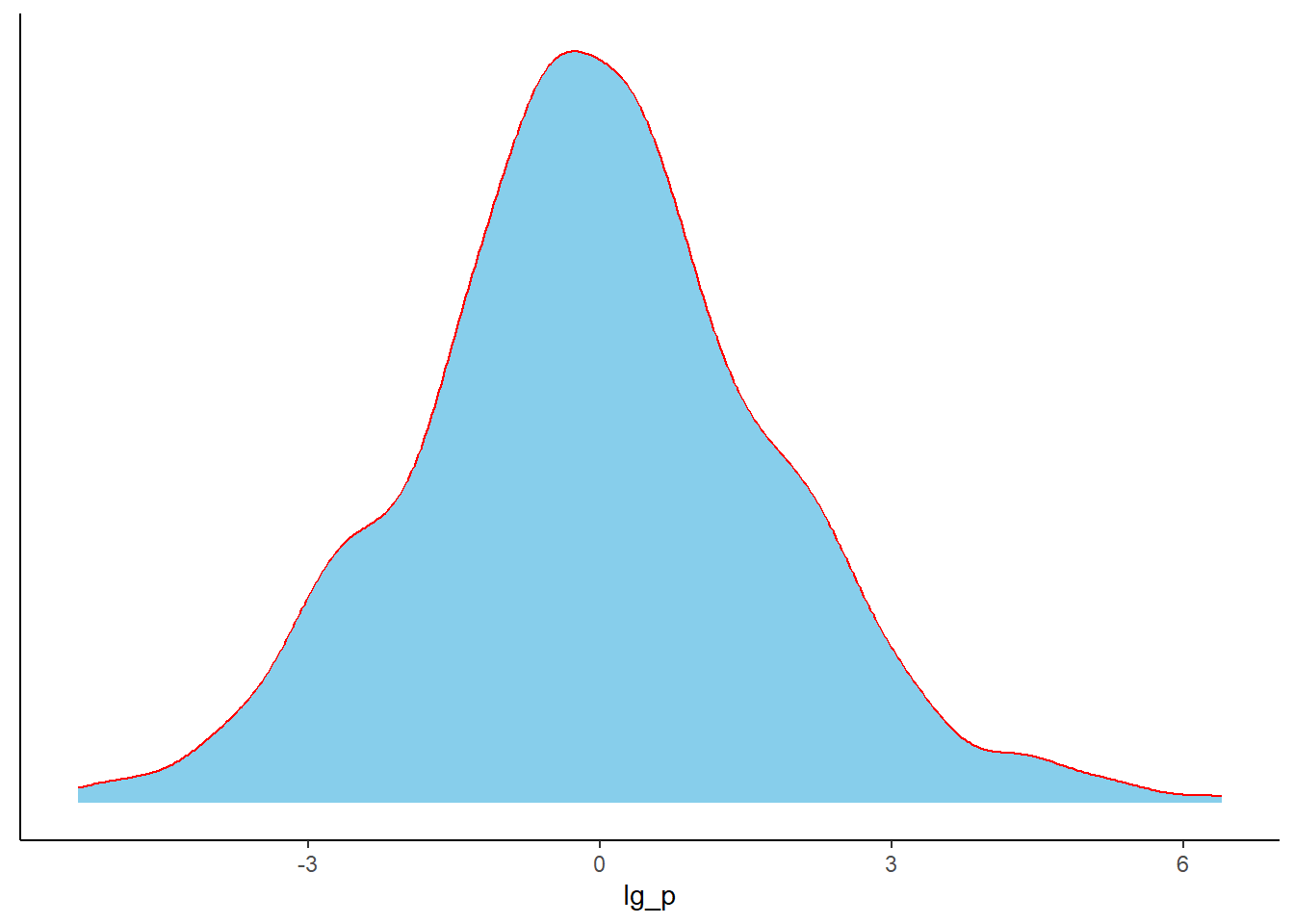
If we don’t want to loss the data from the studies with 0% and 100% event, we need continuity-correction.
“Continuity-corrected proportion usually refers to adjusting a sample proportion by adding a small factor (commonly 0.5) to the numerator and 1 to the denominator.”
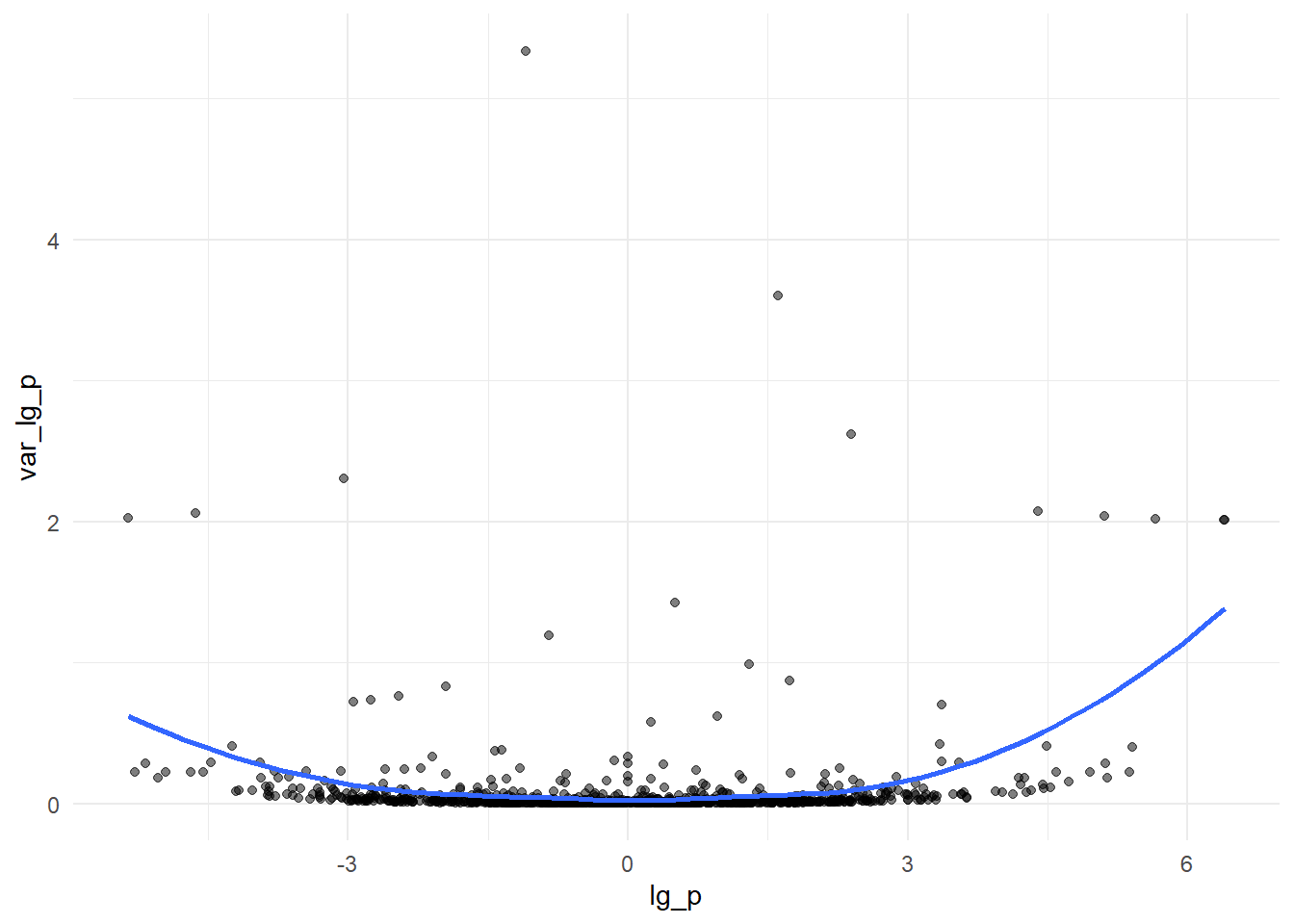
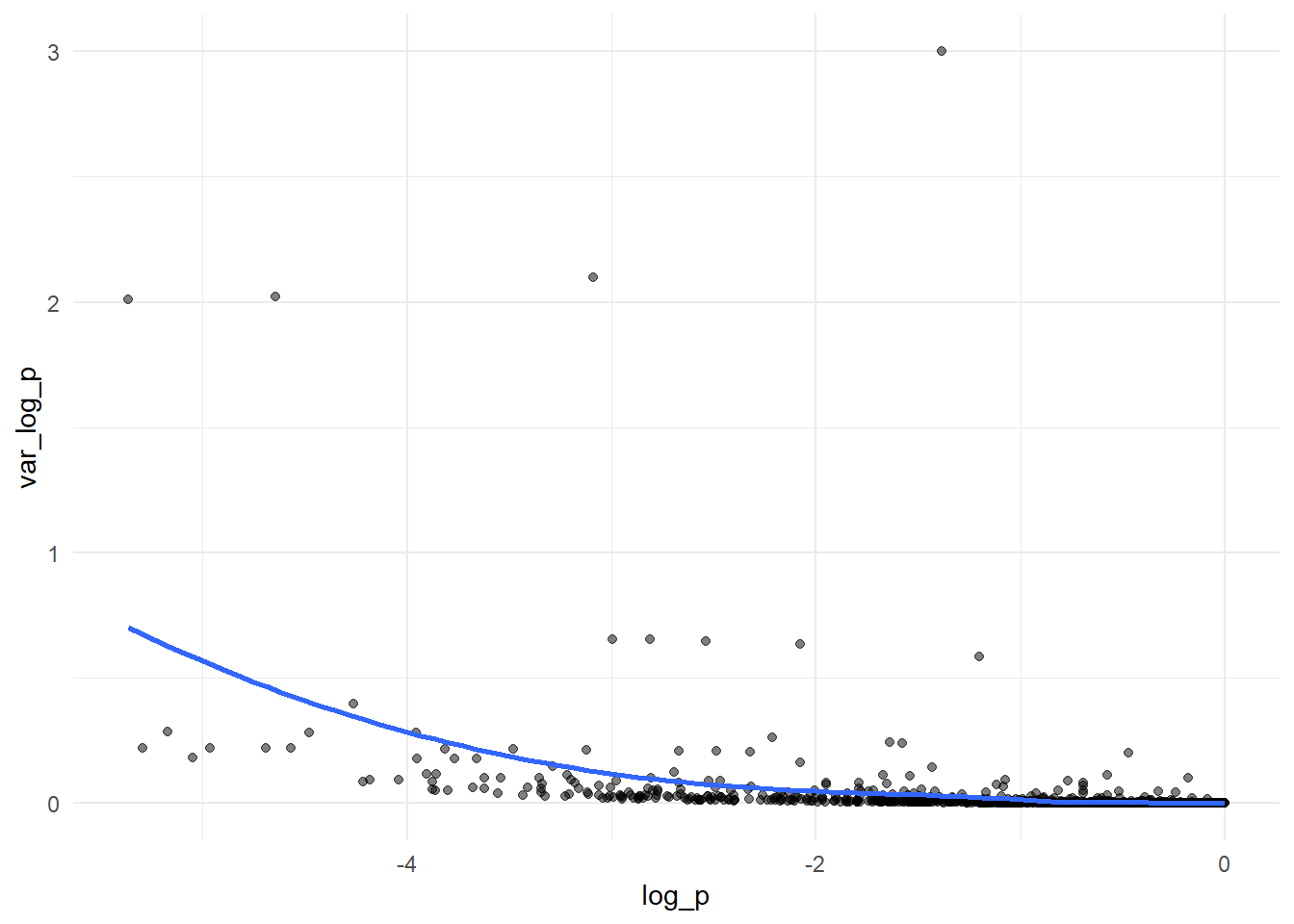
Let’s do that (we have to do the correction for all proportions)
data %>%mutate(p_cc = (p*n +0.5)/(n +1)) %>%mutate(log_p =log(p_cc)) %>%mutate(var_log_p = (1-p_cc)/(n*p_cc)) %>%# another alternative = (1/y) - (1/n)ggplot(.,aes(x = log_p, y = var_log_p))+geom_point(alpha=0.5)+geom_smooth(method ="loess", se =FALSE, formula = y ~ x)+theme_minimal()
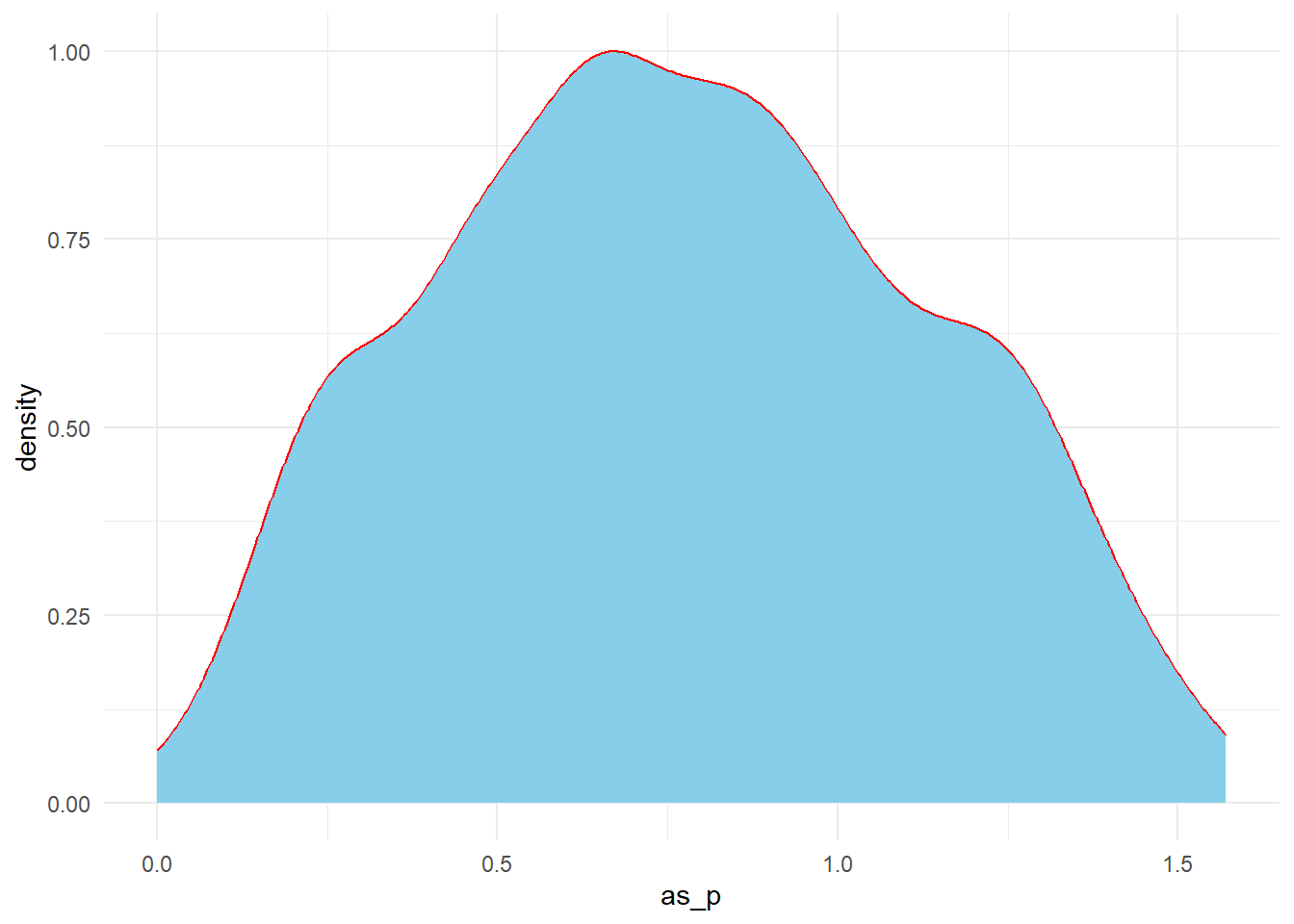
3. Arcsine transformation
arcsine(p)
Code
data %>%mutate(as_p =asin(sqrt(p))) %>%ggplot(.,aes(x = as_p))+geom_density(color ="red",fill ="skyblue")+theme_minimal()
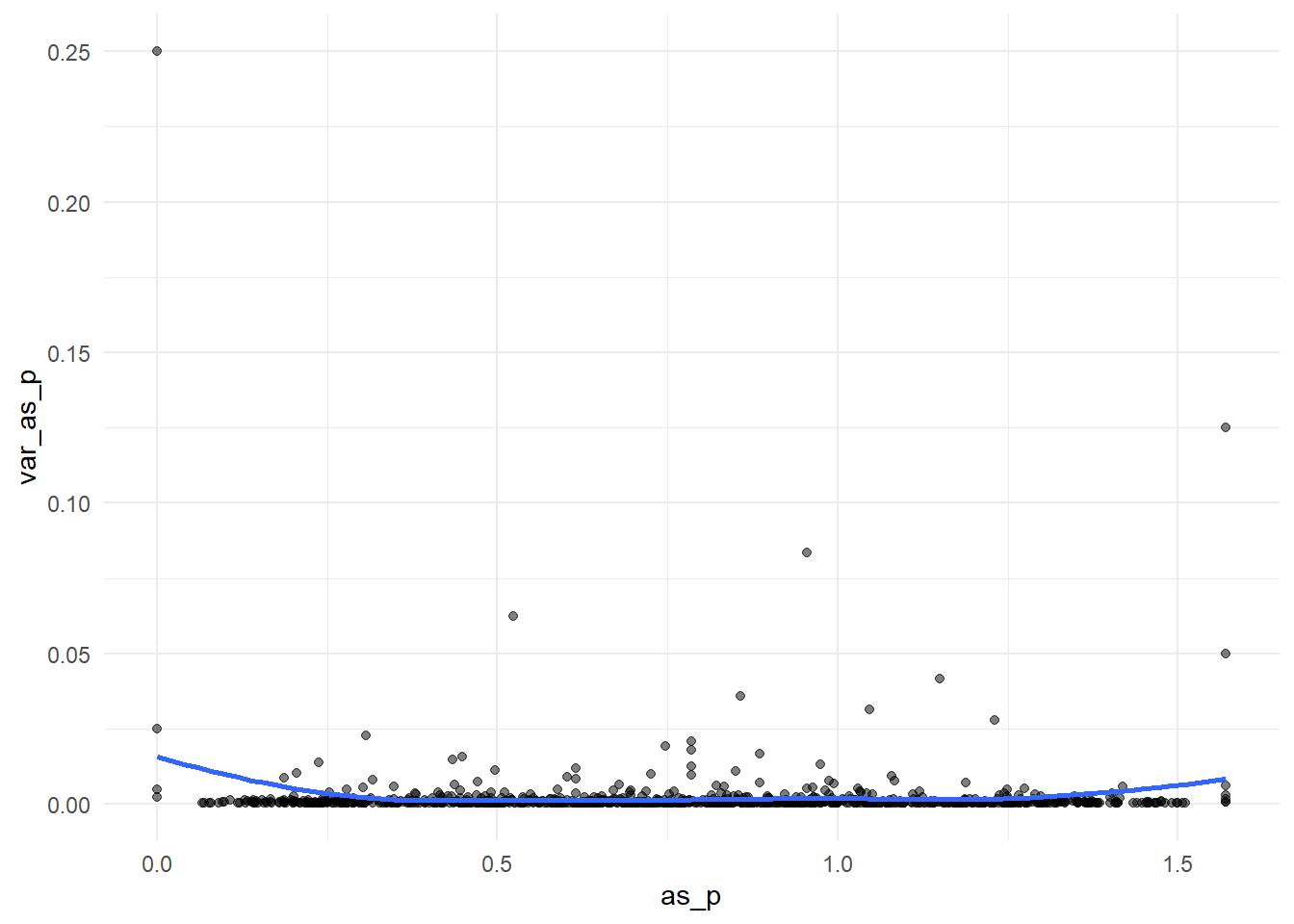
arcsine(p) vs var (arcsine(p))
Code
data %>%mutate(as_p =asin(sqrt(p))) %>%mutate(var_as_p =1/(4*n)) %>%ggplot(.,aes(x = as_p, y = var_as_p))+geom_point(alpha=0.5)+geom_smooth(method ="loess", se =FALSE, formula = y ~ x)+theme_minimal()
4. Freeman–Tukey double arcsine transformation
doublearcsine(p)
Code
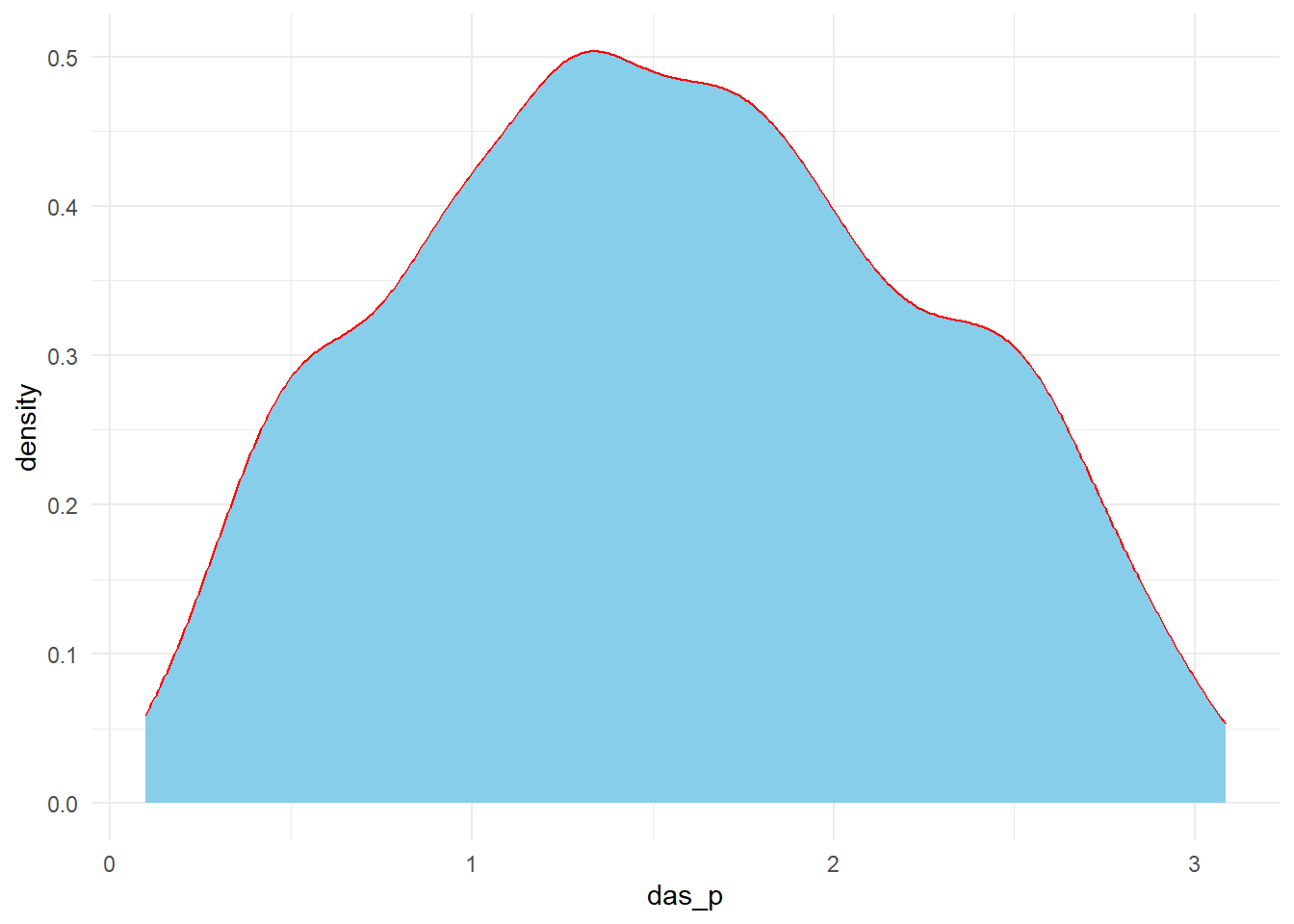
data %>%mutate(das_p =asin(sqrt(y/(n+1))) +asin(sqrt((y+1)/(n+1)))) %>%ggplot(.,aes(x = das_p))+geom_density(color ="red",fill ="skyblue")+theme_minimal()
doublearcsine(p) vs var(doublearcsine(p))
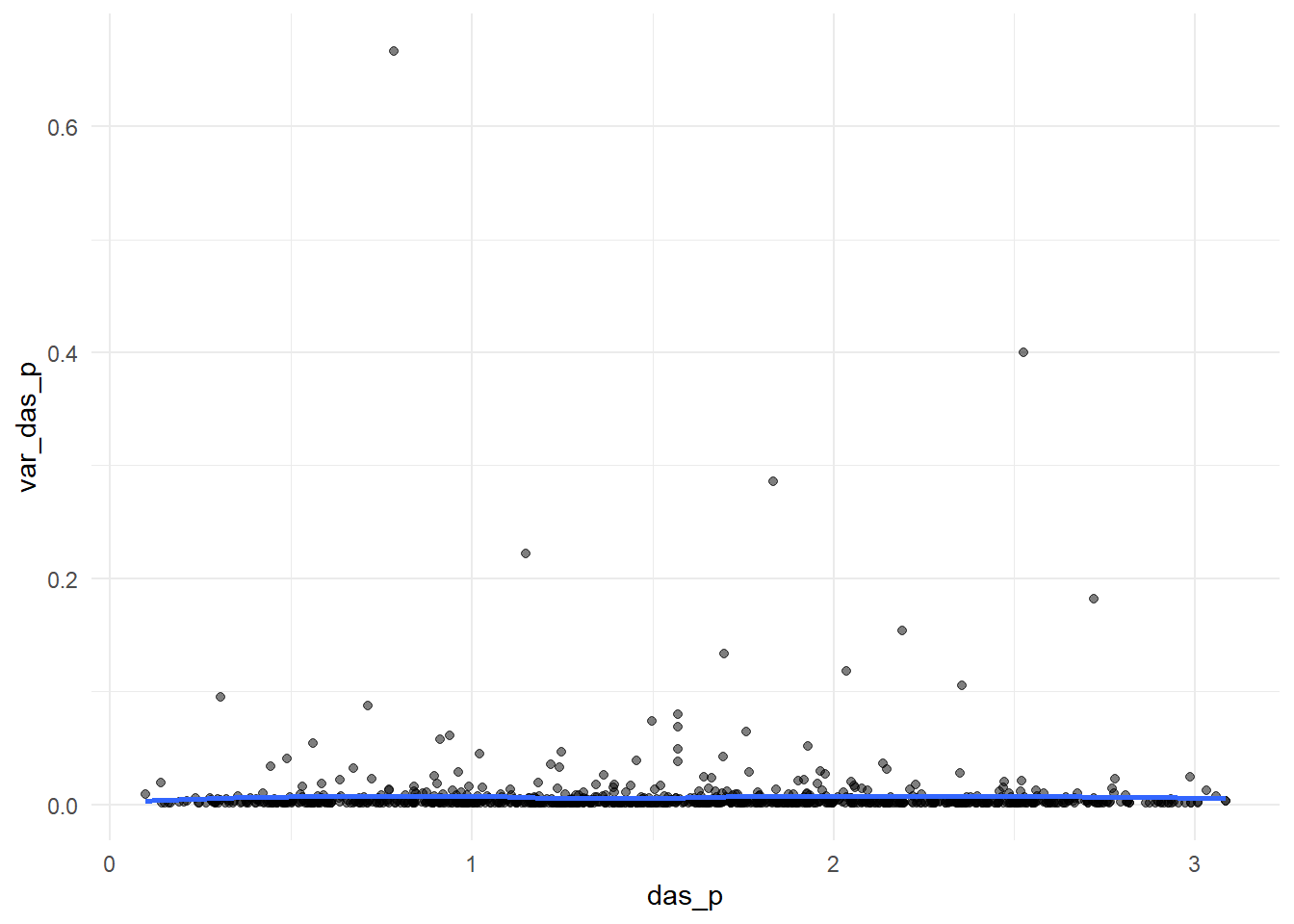
Code
data %>%mutate(das_p =asin(sqrt(y/(n+1))) +asin(sqrt((y+1)/(n+1)))) %>%mutate(var_das_p =1/(n +0.5)) %>%ggplot(.,aes(x = das_p, y = var_das_p))+geom_point(alpha=0.5)+geom_smooth(method ="loess", se =FALSE, formula = y ~ x)+theme_minimal()
So far, we have observed that the logit transformation performs better in improving normality and reducing variance instability. Now, we can go for conducting meta-analysis.
Conducting meta-analysis
1. Choosing the model
The two main parametric models used to combine results from multiple studies are the fixed-effect (FE) and random-effects model (RE).
The FE model assumes that the true proportion is identical across studies included in meta-analysis, and any observed variation in proportion estimates is only due to random sampling error within each study, known as within-study variance.
In contrast, the RE model assumes the true proportions are not the same across studies but follow a normal distribution.
In other words, the RE model accounts for both within-study and between-study variances, while the FE model assumes that the between-study variance is zero (i.e., between-study heterogeneity does not exist) [2,4]. Hackenberger (2020) suggested the use of an FE model if there is no statistical or methodological heterogeneity and if it is not necessary to generalize the conclusions. If a generalized conclusion is the objective and data are available from more than five different studies, a RE model would be appropriate [2,5].
The random-effects model can be estimated by several methods such as -
the method of moments or the DerSimonian and Laird method (DL) and
the restricted maximum likelihood method (REML)
In all cases, the summary effect size (i.e., the summary proportion) is estimated as the weighted average of the observed effect sizes extracted from primary studies. The weighting for each observed effect size is the inverse of the total variance of a study, which is the sum of the within-study variance and the between-study variance. These two methods differ mainly in the estimation of the between-study variance, commonly denoted as τ2 in the meta-analytic literature [4].
2. Estimating summary estimates
The data from multiple studies can be combined following two approaches: (i) classical inverse variance meta-analysis (also known as the two-step method) and (ii) meta-analysis based on generalized linear mixed model (GLMM) [6,7].
Note: In practice, meta-analyses of proportion studies rarely include a very large number of studies (e.g., 1000 studies). For easier visualization and demonstration of the modeling process, we will use the first 20 studies in our examples.
A. Classical inverse variance meta-analysis (two-step method)
This method requires the estimation of the study-specific proportion (or transformed proportion) and its variance (or standard error) in the first step, followed by a second step where the results from multiple studies are combined to get the pooled proportion estimate.
i) A naive way to apply this method will be using metagen() function from meta package: Only for logit transformed proportions
Code
## Transform the proportion (Step-1)data1 <- data %>%slice(1:20) %>%mutate(p_cc = (y +0.5)/(n +1),lg_p =log(p_cc/(1-p_cc)),var_lg_p =1/(n*p_cc)+1/(n*(1-p_cc)),se_lg_p =sqrt(var_lg_p))## Pool transformed proportions (Step-2)model1 <-metagen(TE = lg_p,seTE = se_lg_p,studlab = Study,data = data1 )summary(model1)
However, a comprehensive details of this method has been described by [4]. Now, we will follow that method
ii) Calculate effect size and variance for each study using different transformations
Here, “ies” (short for individual effect size)
A) Without transformation of proportions
Code
data1 <- data %>%slice(1:20) # Create a table with effect sizes and SEsies <-escalc(xi = y, ni = n,data = data1,measure="PR") # measure (=computational method) "PR" used for no transformation#Pool the derived effect sizespes <-rma(yi, #“pes”, which stands for pooled effect size. vi, data = ies, method ="REML")print (pes)
Random-Effects Model (k = 20; tau^2 estimator: REML)
tau^2 (estimated amount of total heterogeneity): 0.0943 (SE = 0.0310)
tau (square root of estimated tau^2 value): 0.3071
I^2 (total heterogeneity / total variability): 99.73%
H^2 (total variability / sampling variability): 376.25
Test for Heterogeneity:
Q(df = 19) = 10327.6360, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.4389 0.0691 6.3497 <.0001 0.3034 0.5744 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
B) With logit transformation of proportions
Code
# Create a table with effect sizes and SEsies.logit <-escalc(xi = y, ni = n,data = data1,measure="PLO") # measure (=computational method) "PLO" used for logit transformation#Pool the derived effect sizespes.logit <-rma(yi, #“pes”, which stands for pooled effect size. vi,data = ies.logit)# Inverse of logit transformationpes_predict <-predict (pes.logit, transf = transf.ilogit)print (pes_predict)
pred ci.lb ci.ub pi.lb pi.ub
0.4154 0.2472 0.6059 0.0207 0.9598
C) With double arcsine transformation of proportions
Code
# Create a table with effect sizes and SEsies.da <-escalc(xi = y, #da for double arcsineni = n,data = data1,measure="PFT") # measure (=computational method) "PFT" used for double arcsine transformation transformation#Pool the derived effect sizespes.da <-rma(yi, #“pes”, which stands for pooled effect size. vi,data = ies.da)# Inverse of double arcsine transformationpes_predict <-predict (pes.da, transf = transf.ipft.hm, targ =list(ni = data1$n))#Alternatively we can do back transformation as foloows:# (I just don't want to use this way at this moment,That is why i am putting the "#" before code) #pes_predict <- predict (pes.da , transf = transf.ipft.hm, targ = list (ni =1/( pes.da$se )^2) )print (pes_predict)
pred ci.lb ci.ub pi.lb pi.ub
0.4290 0.2778 0.5872 0.0000 0.9844
Here, we will use the logit transformation. As I mentioned earlier, we can estimate RE model using different estimator. Now, we will do that
iii) RE model estimation with different estimators (only logit transformed data)
A) DL: Most popular method
Code
ies.logit <-escalc(xi = y, ni = n,data = data1,measure="PLO") #Pool the derived effect sizespes.logit_dl <-rma(yi, vi,data = ies.logit,method ="DL",level =95)# Inverse of logit transformationpes_predict_dl <-predict (pes.logit_dl, transf = transf.ilogit)print (pes_predict_dl)
pred ci.lb ci.ub pi.lb pi.ub
0.4151 0.2892 0.5531 0.0541 0.8981
This is our chosen model
B) REML
Code
#Pool the derived effect sizespes.logit_reml <-rma(yi, #“pes”, which stands for pooled effect size. vi,data = ies.logit,method ="REML")# Inverse of logit transformationpes_predict <-predict (pes.logit_reml, transf = transf.ilogit)print (pes_predict)
pred ci.lb ci.ub pi.lb pi.ub
0.4154 0.2472 0.6059 0.0207 0.9598
C) ML
Code
#Pool the derived effect sizespes.logit_ml <-rma(yi, #“pes”, which stands for pooled effect size. vi,data = ies.logit,method ="ML")# Inverse of logit transformationpes_predict <-predict (pes.logit_ml, transf = transf.ilogit)print (pes_predict)
pred ci.lb ci.ub pi.lb pi.ub
0.4154 0.2509 0.6012 0.0226 0.9562
B. Meta-analysis based on generalized linear mixed model (GLMM)
As an alternative to the classical inverse variance method, GLMM can be used to conduct meta-analysis of proportions. The major advantage of this method is that it does not require any data transformation or manual variance calculation at the study level. GLMMs can directly model the even counts (cases) with a binomial likelihood.
For \(K\) independent studies, if \(y_i\) , \(n_i\) , \(p_i\) , and \(\varepsilon_i\) represent the number of case (or event), sample size, true proportion and random-effects for study i, GLMM can be specified as follows:
Likelihood:
\[
y_i \sim \text{Binomial}(n_i,p_i)
\]
Link function:
\[
\text{logit}(p_i) = \mu + \varepsilon_i
\]
Random effects:
\[
\varepsilon_i \sim \text{Normal}(0,\tau^2)
\]
Here, P is the overall proportion on the transformed scale, and τ2 is the between-study variance. Various links (i.e., transformation) are widely used in GLMMs, including the identity, log, logit, probit, cauchy, etc. The synthesized pooled estimate is required to be back-transformed into the original proportion scale if a link function other than identity is used.
=============We will discuss GLMM method in another tutorial =======
3. Presentation of results (forest plot)
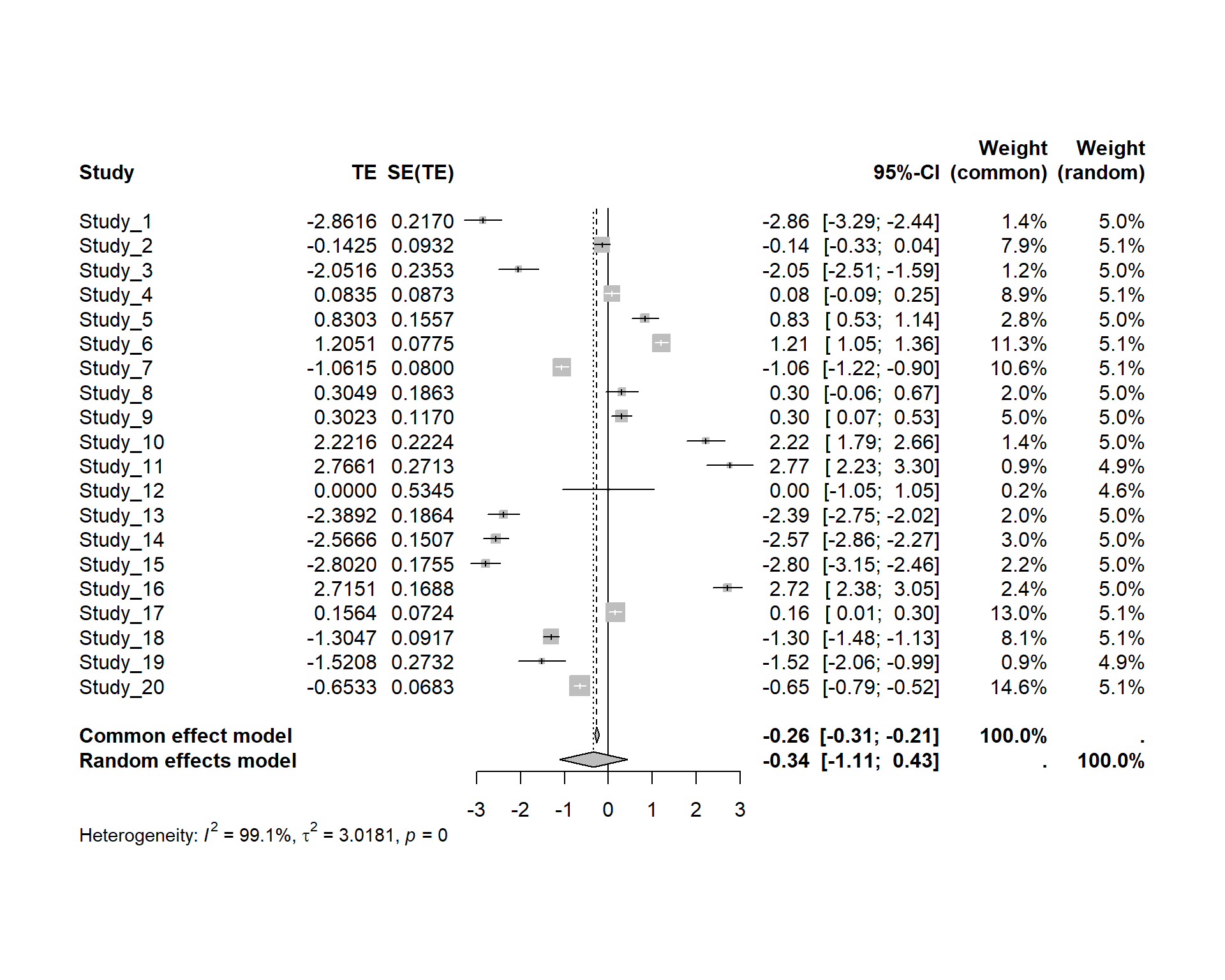
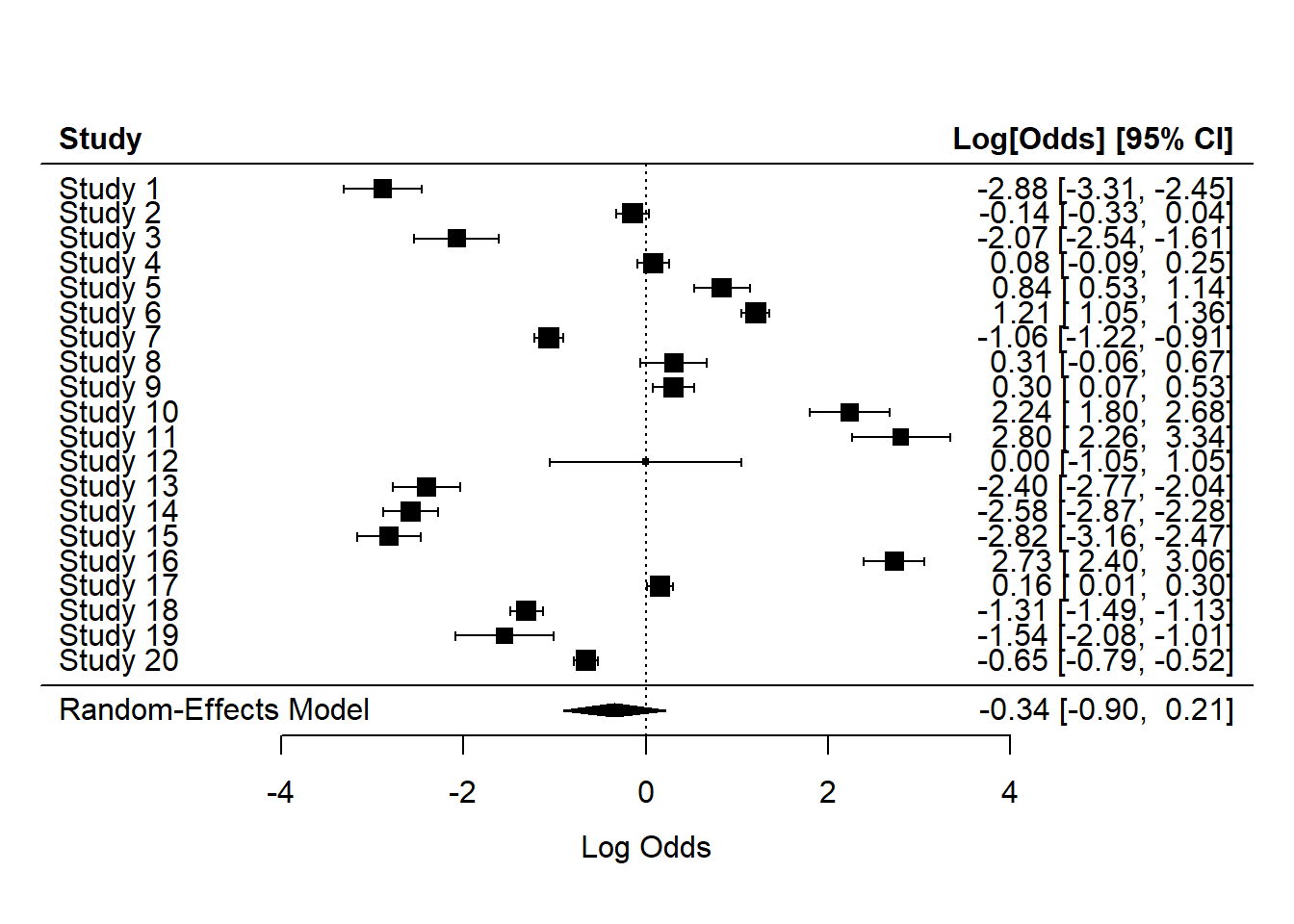
Forest plot for our naive way
Code
forest(model1)
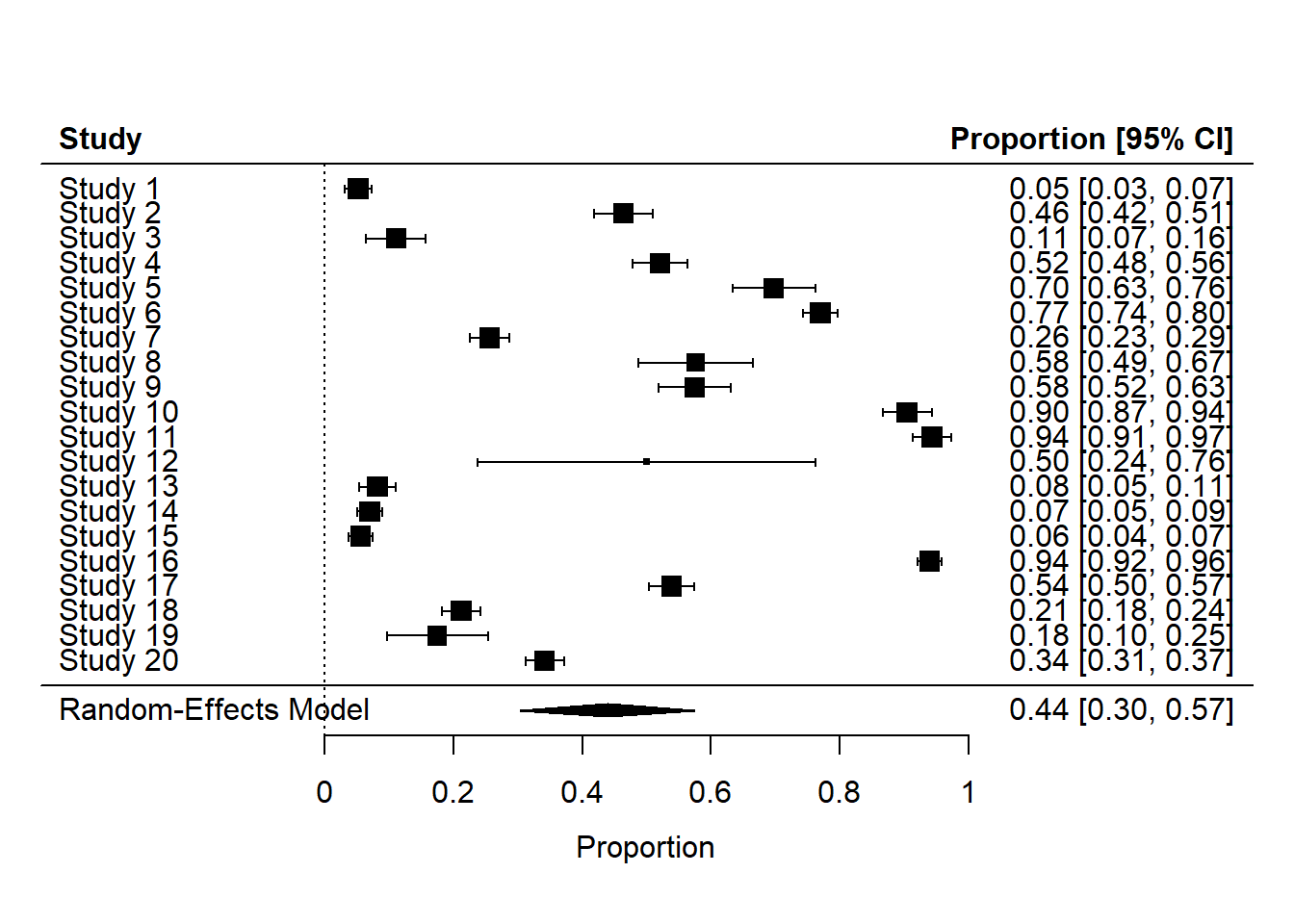
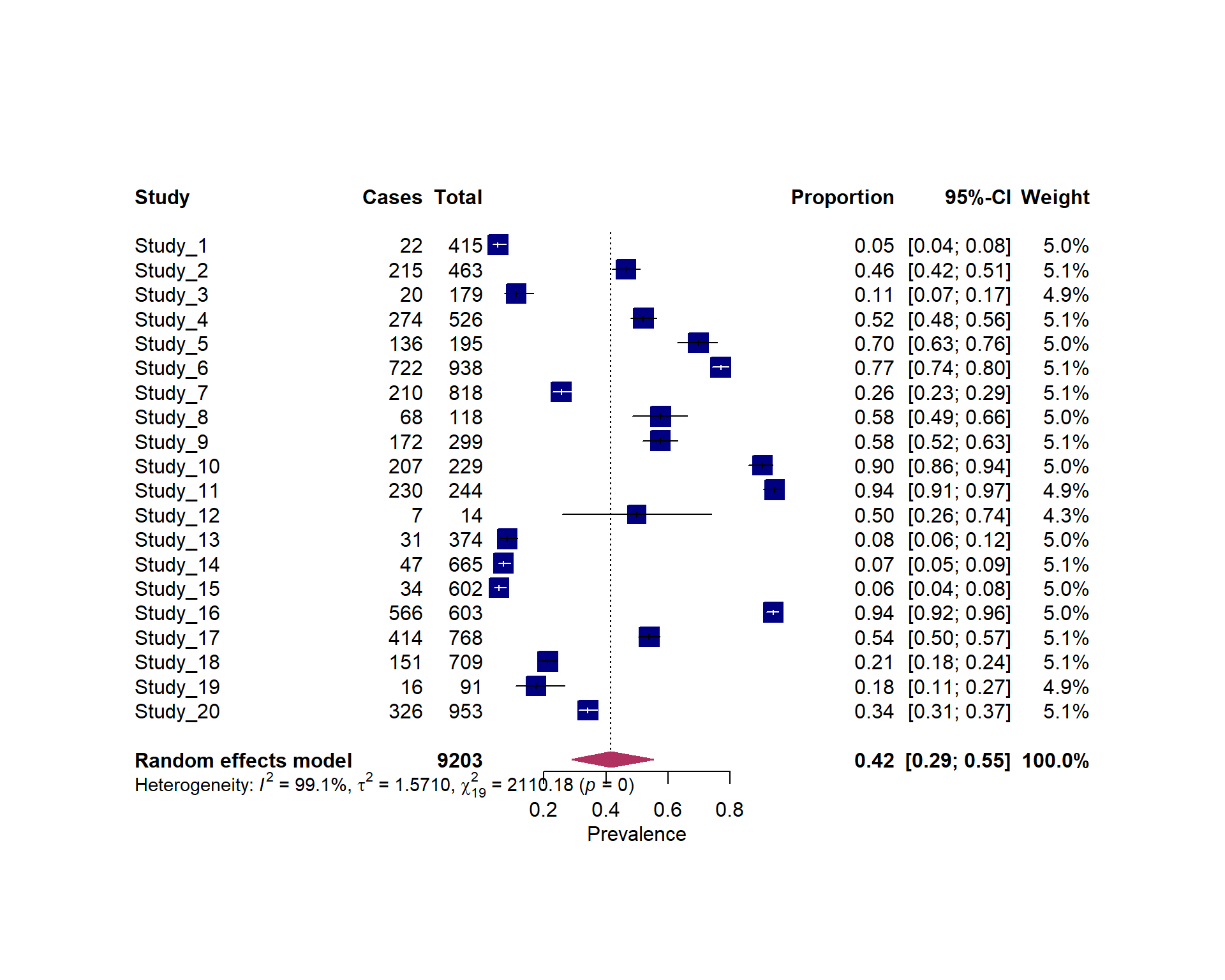
Forest plot for the meta-analysis of raw proportion
Code
#| fig.width: 10#| fig.height: 8forest(pes)
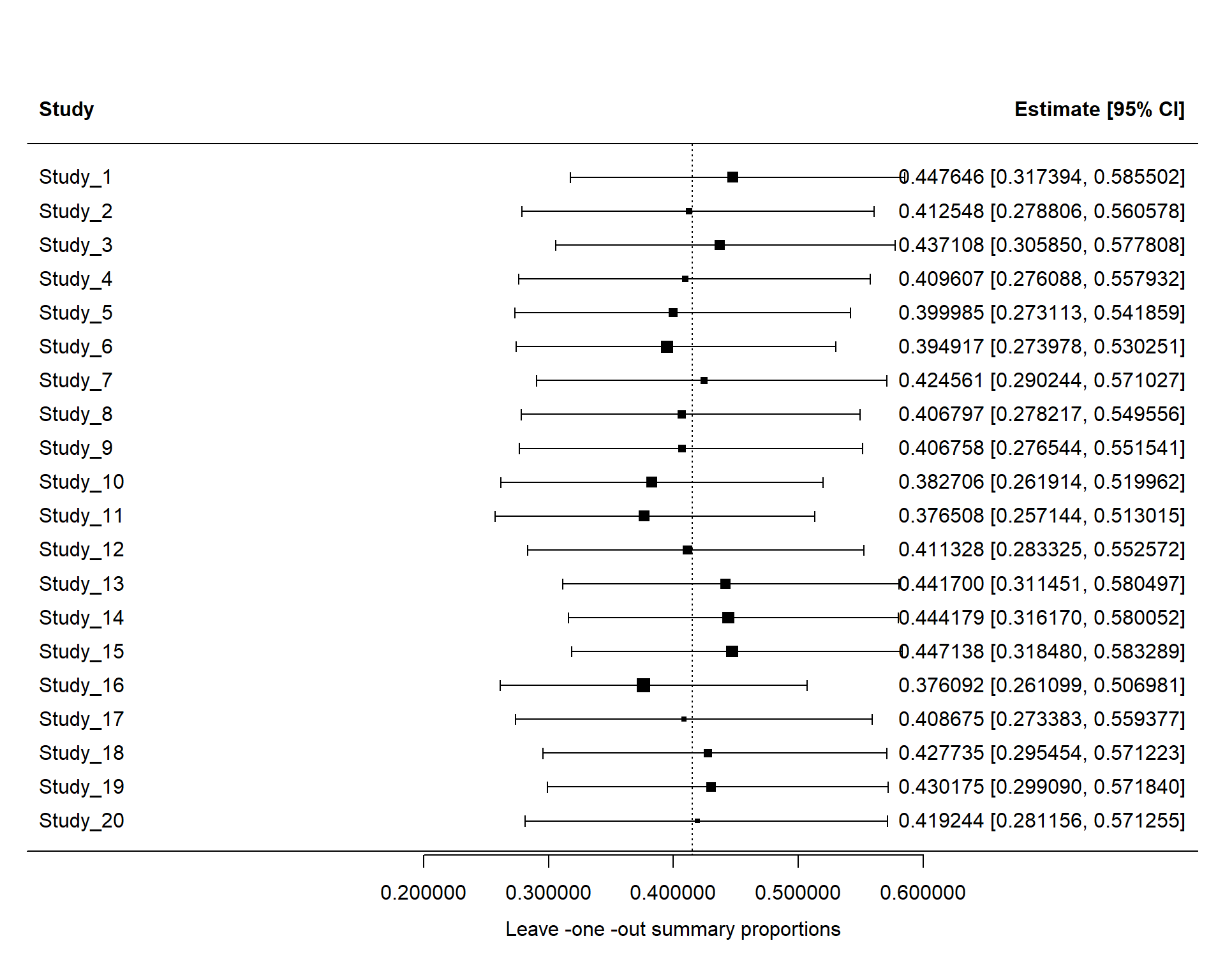
Forest plot for the meta-analysis of raw proportion logit transformed proportions
There are three quantifying statistics for heterogeneity.
1) The between-study variance (tau^2): Also known as tau-squared statistic.It reflects the total amount of systematic difference in effects across studies.Sensitive to sample size of the studies included
2) Test of heterogeneity: Cochran’s Q : The statistical power of the Q-test heavily relies on the number of studies included in a meta-analysis, and as a result, it may fail to detect heterogeneity due to limited power when the number of included studies is small (less than 10) or when the included studies are of small size. It only assesses the viability of the null hypothesis and does not provide a quantification of the magnitude of the true heterogeneity in effect sizes
3) I^2 statistic: unaffected by the number of included studies.I2 can take values from 0% to 100%. A value of 0% indicates that all heterogeneity is caused by sampling error alone, requiring no further explanation. I2 Conversely, when equals 100%, the entire heterogeneity can be attributed ex clusively to genuine differences between studies, thus justifying the application of subgroup analyses or meta-regressions to identify potential moderating factors.As a thumb rule, 25%, 50%, and 75% are commonly used to indicate low, medium, and high heterogeneity, respectively.
Code
print(pes.logit_dl)
Random-Effects Model (k = 20; tau^2 estimator: DL)
tau^2 (estimated amount of total heterogeneity): 1.5710 (SE = 0.6875)
tau (square root of estimated tau^2 value): 1.2534
I^2 (total heterogeneity / total variability): 99.10%
H^2 (total variability / sampling variability): 111.06
Test for Heterogeneity:
Q(df = 19) = 2110.1804, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
-0.3429 0.2838 -1.2085 0.2269 -0.8991 0.2132
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This included subgroup analysis and meta-regression; however, these methods will not be demonstrated in this example.
6. Identifying the influential studies
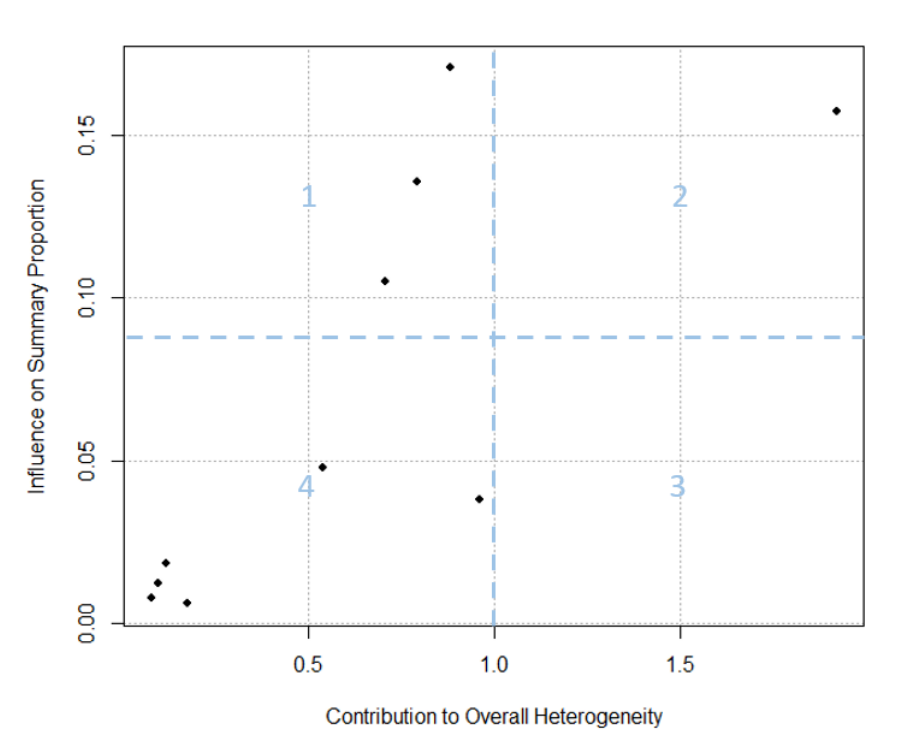
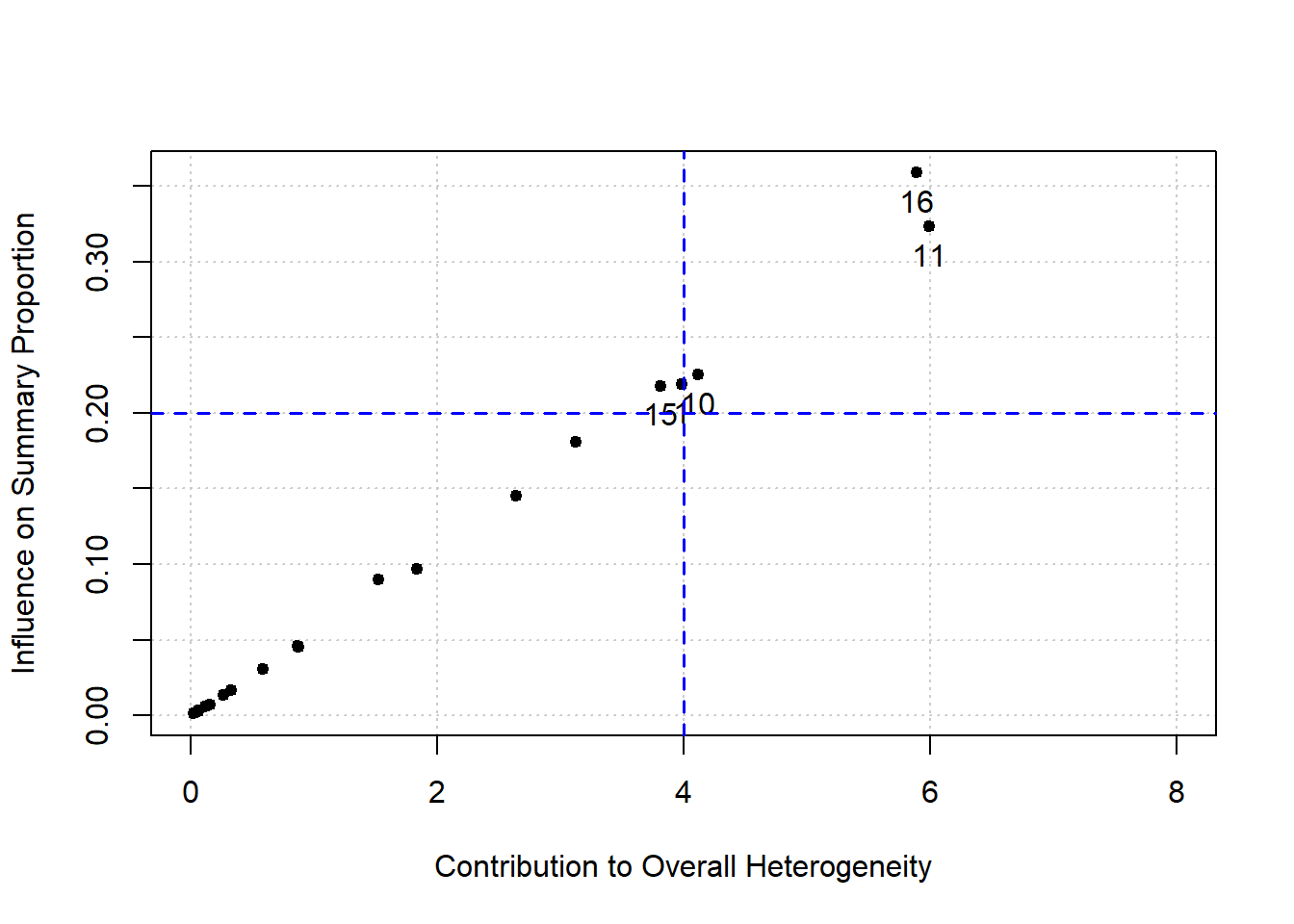
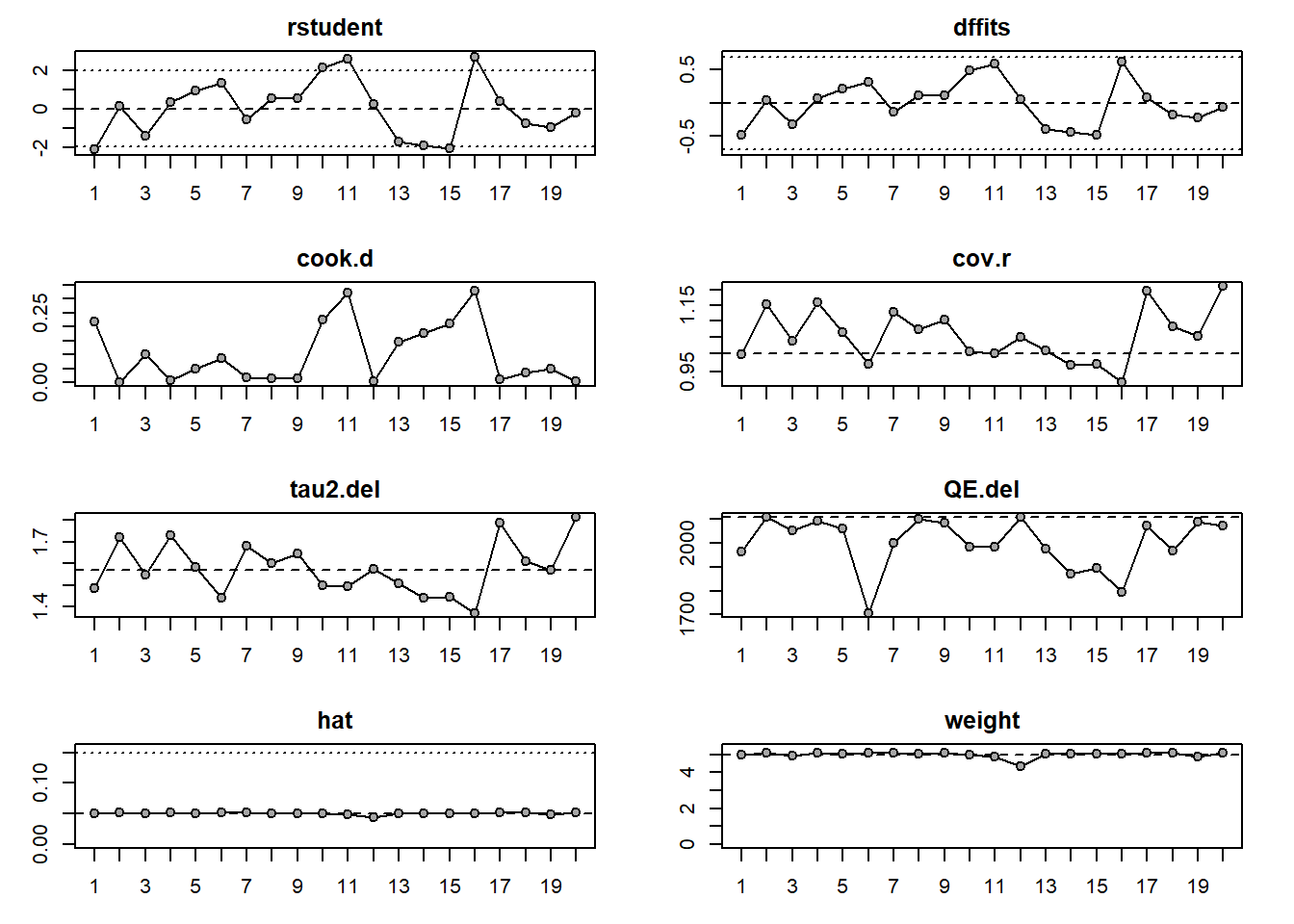
A. Identifying outlying and influential studies with diagnostic tools (Baujat plot)
General description
The Baujat plot helps distinguish between outliers that are influential and those that are not [4]:
Small studies with effect sizes similar to others typically fall into the lower left corner of Quadrant 4, indicating they are neither outliers nor influential. Q4: not-influential-not-outlier
Small studies with notably different effect sizes than others often appear in the lower right corner of Quadrant 3. They may be outliers, but their small sample sizes prevent them from heavily impacting the overall effect size. Q3: not-influential-outlier
Large studies with dramatically different effect sizes than the rest tend to appear in the upper right corner of Quadrant 2. These studies are influential outliers, exerting the most substantial impact on both the overall effect and heterogeneity. Q2: influential-outlier
Large studies with effect sizes similar to the majority of effect sizes tend to populate the upper left corner of Quadrant 1. While these studies have influential effects, they may not be outliers. Their influence on the pooled effect size is pronounced because of their extensive sample sizes. Q1: nfluential-not-outlier
Surprisingly, removal of any study did not change the estimate significantly (for example, > 10%). But close to 10% change happened for removing Study 16. Now, vizualize the results
No study was marked with asterisk (*). Now, we can check different plot
Code
plot (inf)
No studies had red color
In conclusion, Baujat plots identified several studies with relatively large contributions to heterogeneity and/or pooled effect estimation. However, leave-one-out diagnostics showed that omission of these studies did not materially alter the pooled estimate or heterogeneity statistics, suggesting that no single study exerted undue influence on the overall meta-analysis results.
7. Searching for publication bias (Optional)
One of the major threats to the validity of meta-analyses is publication bias [4]. Current methods (e.g., funnel plot, trim-and-fill method, Egger’s regression model, etc.) for detecting publication bias and its impact assume that large studies or studies with significant results are most likely to be published. While this assumption might be logical for other types of studies (e.g., randomized control trials), it does not fit proportion studies. Most proportion studies are observational, non-comparative, and may be context-specific. They inherently preclude the testing of statistical significance for their findings. Therefore, the application of existing methods of addressing publication bias is not recommended in meta-analyses of proportion or prevalence studies[8].
However, some researchers publish funnel plot and other statistics.
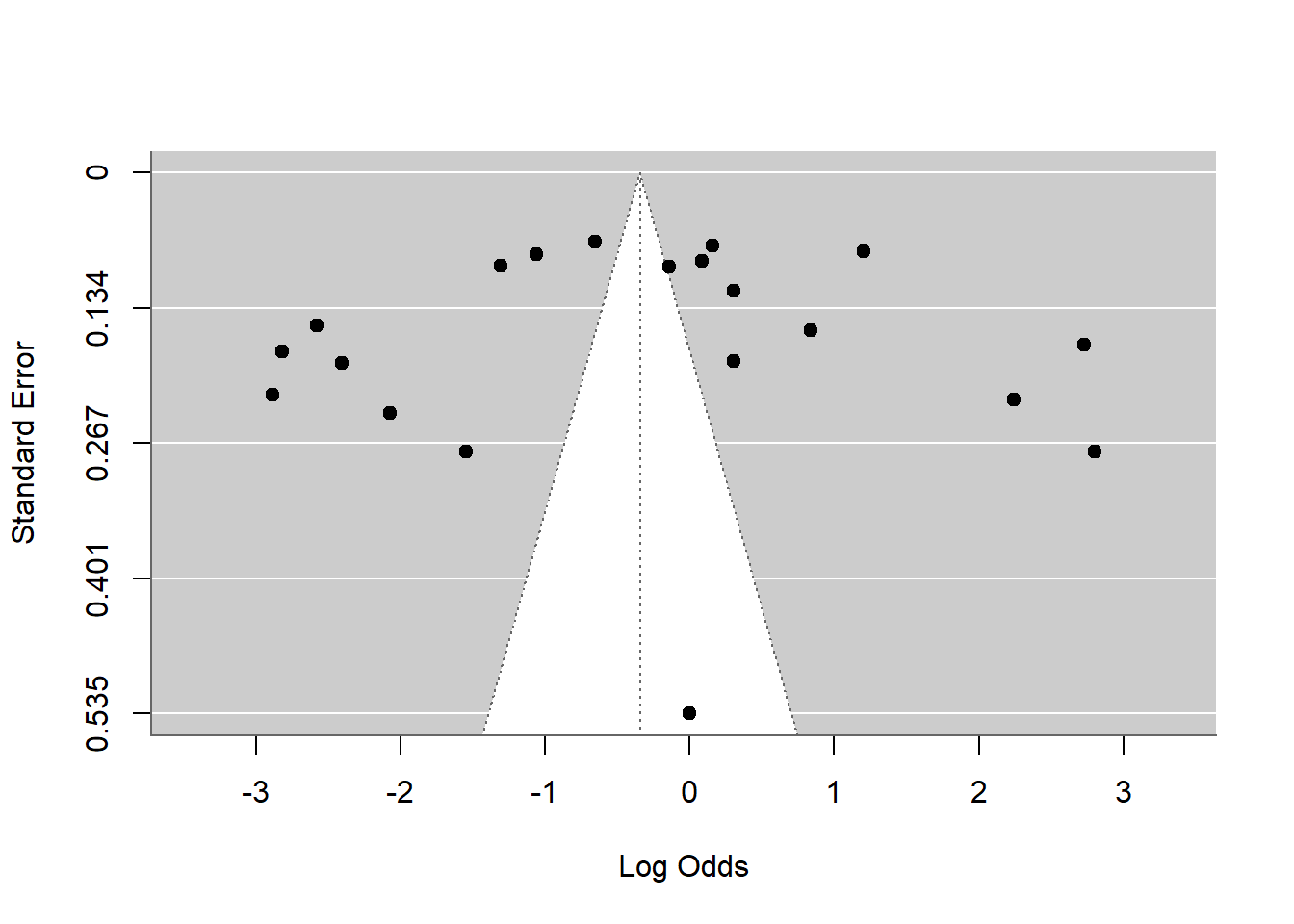
A. Funnel plot
Code
funnel(pes.logit_dl)
Caution!!!
In prevalence/proportion meta-analysis, asymmetry may arise from:
true heterogeneity,
varying sample sizes,
rare events,
transformation artifacts,
or methodological differences,
not necessarily publication bias. So funnel plot asymmetry alone is insufficient evidence.
B. Egger’s test
Code
regtest(pes.logit_dl, model ="rma")
Regression Test for Funnel Plot Asymmetry
Model: mixed-effects meta-regression model
Predictor: standard error
Test for Funnel Plot Asymmetry: z = 0.1430, p = 0.8863
Limit Estimate (as sei -> 0): b = -0.4120 (CI: -1.5146, 0.6907)
However, Egger’s test can produce inflated false positives in proportion meta-analysis, especially when:
prevalence is very low/high,
heterogeneity is substantial,
number of studies is small.
C. Peters’ test
Code
regtest(pes.logit_dl, predictor ="ni")
Regression Test for Funnel Plot Asymmetry
Model: mixed-effects meta-regression model
Predictor: sample size
Test for Funnel Plot Asymmetry: z = -0.5592, p = 0.5760
D. Trim-and-fill
Code
taf <-trimfill(pes.logit_dl)funnel(taf)
What are the major limitations of two step method?
This method might not work well when the study sample sizes are small. In those cases, the variance becomes unstable, leading to unreliable weights for the study.
It may require the transformation of study-level proportions, and each transformation has its own limitations. For example, the log and logit transformations impractically treat within-study variances as fixed, known values and require ad hoc corrections for zero counts. The results from arcsine-based transformations may lack interpretability.
References
1.
Dohoo IR, Martin WS, Stryhn H. Chapter 28: Systematic review and meta-analysis. 2nd ed. Veterinary epidemiologic research. 2nd ed. Charlottetown, Canada: VER, Incorporated; 2014.
2.
Hackenberger BK. Bayesian meta-analysis now–let’s do it. Croatian Medical Journal. 2020;61: 564.
3.
Barker TH, Migliavaca CB, Stein C, Colpani V, Falavigna M, Aromataris E, et al. Conducting proportional meta-analysis in different types of systematic reviews: A guide for synthesisers of evidence. BMC medical research methodology. 2021;21: 189.
4.
Wang N. Conducting meta-analyses of proportions in r. Journal of Behavioral Data Science. 2023;3: 64–126.
5.
Munn Z, Moola S, Lisy K, Riitano D, Tufanaru C. Methodological guidance for systematic reviews of observational epidemiological studies reporting prevalence and cumulative incidence data. JBI Evidence Implementation. 2015;13: 147–153.
6.
Lin L, Chu H. Meta-analysis of proportions using generalized linear mixed models. Epidemiology. 2020;31: 713–717.
7.
Schwarzer G, Rücker G. Meta-analysis of proportions. Meta-research: Methods and protocols. Springer; 2021. pp. 159–172.
8.
Borenstein M. Common mistakes in meta-analysis and how to avoid them. (no Title). 2019.